深入理解 MCP(Model Context Protocol)搭配簡易實作
隨著大語言模型逐漸成為各種工具與應用的核心,引入外部資源與工具來增強模型能力已成為普遍的技術需求。本文將深入探討MCP(Model Context Protocol),並透過實際範例詳解如何從零開始建立並連結 MCP 工具至主流 AI 應用。
什麼是 MCP?
MCP 全名為 Model Context Protocol,中文稱作「模型上下文協定」,是一種開放標準協定,由開發知名 AI 模型「Claude」的美國新創公司 Anthropic 於 2024 年 11 月所推出。MCP 提供一種標準化的方式,讓 AI 模型可以向外部工具或服務請求數據並使用相關功能。這個協議提供了一個統一介面,可將自訂工具與資源整合至不同的 AI 應用中,從而讓開發者可以輕鬆連結各種自定義工具(例如文件檢索、資料庫查詢)至 Cursor、Windsurf、Claude Desktop、GitHub Copilot 等多種平台。目前已有數個工具和供應商支援 MCP,這使得其應用範圍更加豐富且靈活。
我們可以將 MCP 視為 AI 應用程式中的「USB-C 介面」,它提供一個標準化且即插即用的方式來連接各種工具和數據。就像 USB-C 可讓不同品牌的設備彼此兼容,MCP 也制定了一套通用規範,使得任何基於大型語言模型的客戶端都能與所有符合 MCP 標準的伺服器進行互動。從架構上看,MCP 透過內嵌於應用程式中的客戶端連接 AI 主機(例如 Claude 或各種 IDE),再與各個 MCP 伺服器對接,而這些伺服器則猶如各類外接裝置,不論是遠端服務(如 Slack、Gmail、日曆 API 等)或是本地資料(例如文件和資料庫),皆能透過統一的 MCP 介面實現連結,讓 AI 助手得以輕鬆存取並整合多元數據和工具。
對於 AI 工具開發者來說,只需建立一個 MCP 伺服器,便能讓所有大型語言模型輕鬆存取各種工具和數據來源,無需為每個模型獨立開發 API。
為何需要 MCP?
MCP(Model Context Protocol)是一個開放的通訊協定,透過該協定,所有應用都能以標準化的方式與LLM溝通。因此,MCP並非全能的AI助手、應用程式,或程式語言,而是一個標準化的溝通協定。其目標是有效率地將開發好的外部工具與資源連結到各種AI應用中,概念上與 LangChain 中的 bind_tools 方法,以及 OpenAI 的 Function Calling/tool use 相當,但 MCP 將此概念更進一步擴展至多個AI應用的統一整合。
- MCP 不是全能的 AI 助手,只是一個統一的溝通橋樑。
- MCP 不是一款應用程式,而是一個標準化協定。
- MCP 不是一種獨立的服務,而是一個連接多種服務的介面。
- MCP 不是一個 LLM,其作用在於連接 LLM 與外部資源。
- MCP 不是一種程式語言,而是用來定義如何進行跨平台溝通的規範。
- MCP 不是一個單一工具,而是連接各種外部工具和資源的橋樑。
MCP 解決什麼問題?
在未啟用 MCP 前,大型語言模型(LLM)無法直接存取 GitHub 的最新 commit、Google 日曆資訊、Gmail 信件等外部訊息。雖然 Tool use (function calling) 的概念可以在某些特定框架中實現資料調用,但這種方法通常受限於框架綁定,難以快速移植到其他應用,且常面臨呼叫失敗或錯誤處理不足的問題。有了 MCP,透過一個中介伺服器,LLM 能夠統一存取並處理這些外部資料,並進一步生成摘要或其他回應。這不僅簡化了資料調用的流程,還大幅提升了系統的穩定性與擴展性。
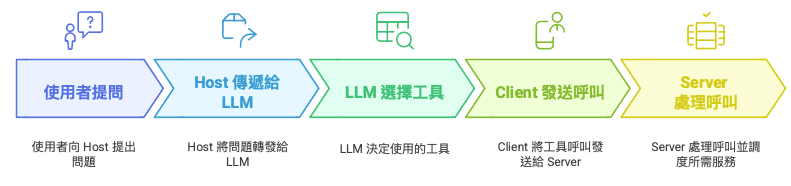
MCP 如何運作?
MCP 的設計遵循客戶端-伺服器架構,將 AI 應用程式和數據連接器的角色清楚區分。其主要組成部分包括:
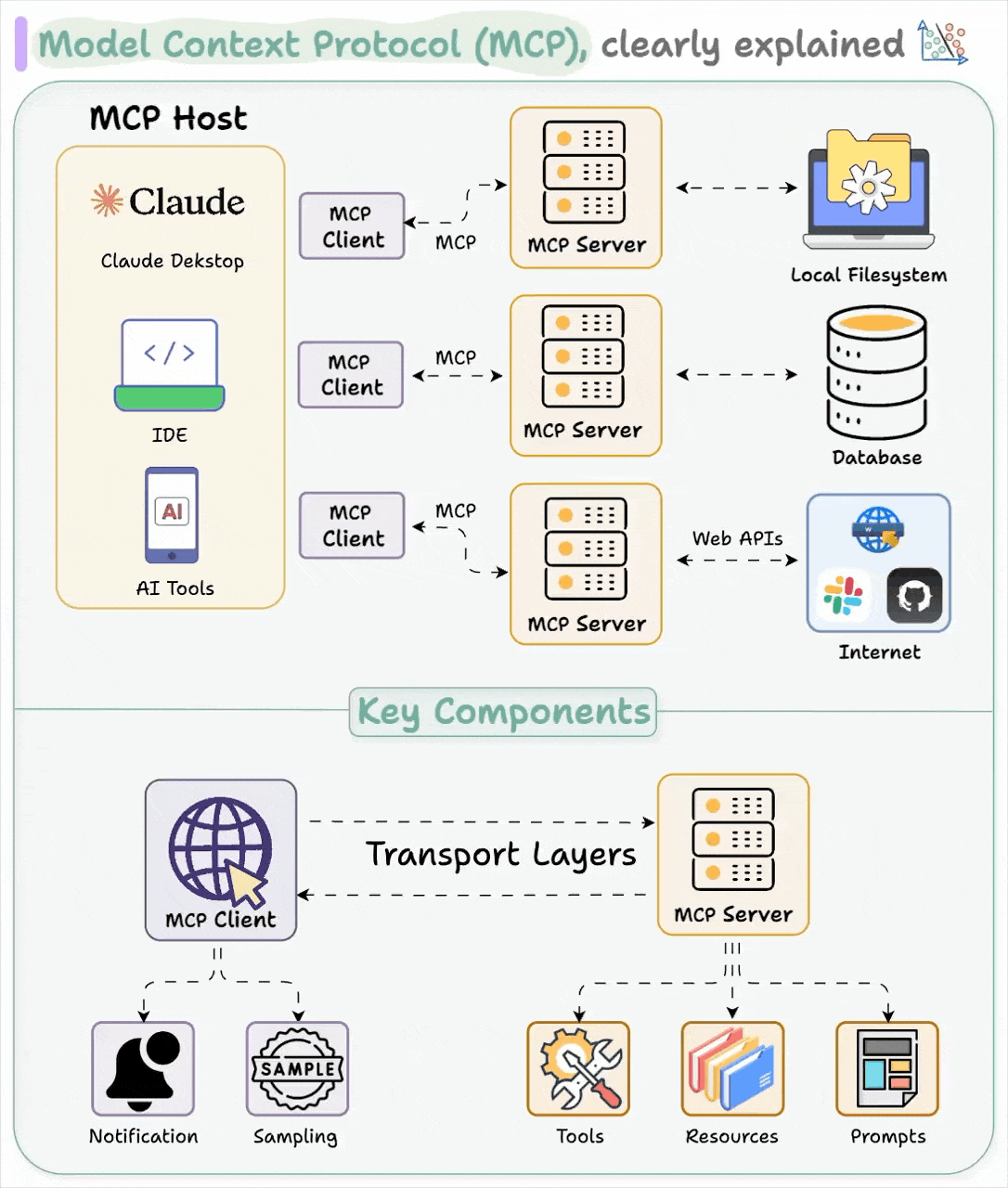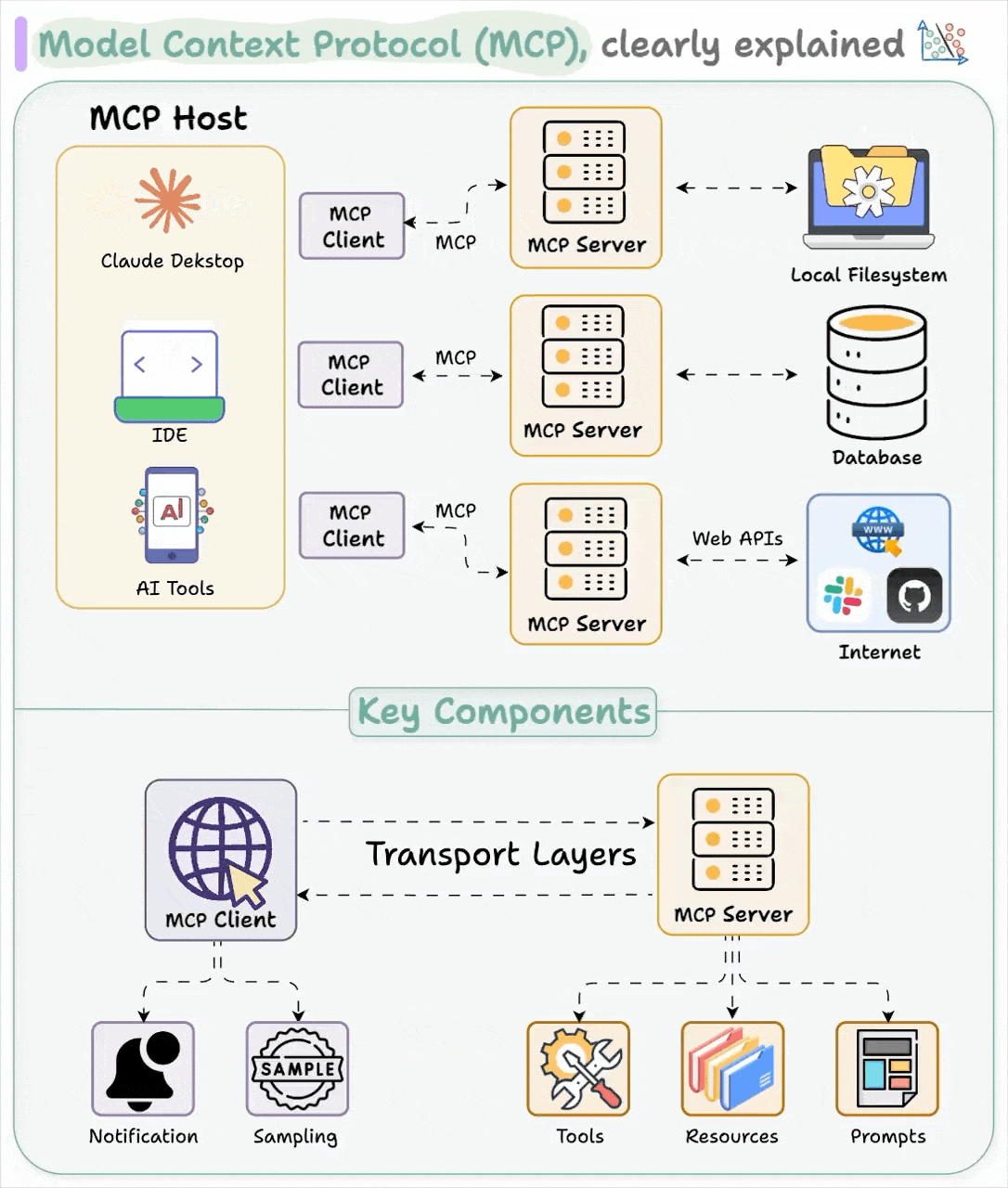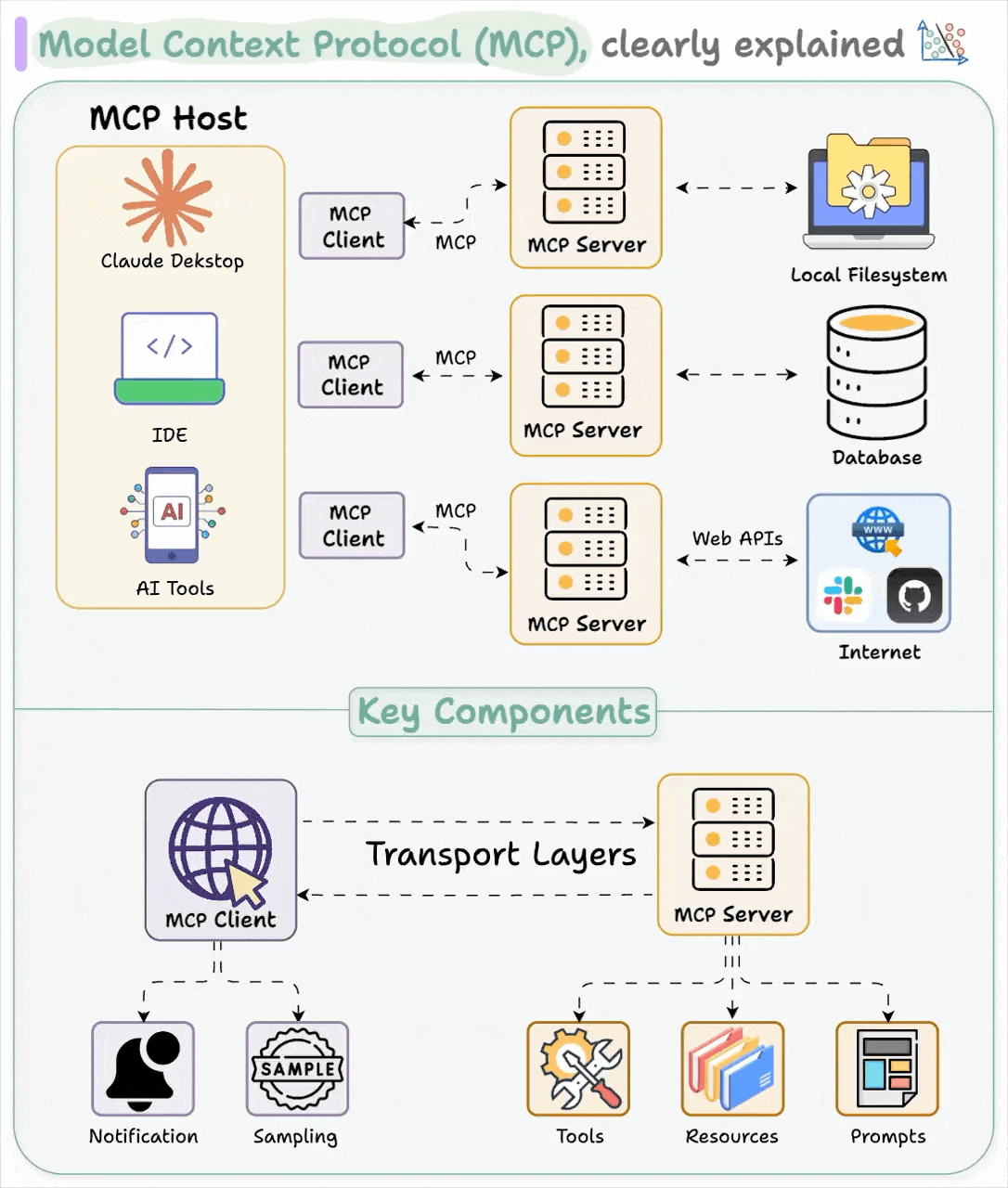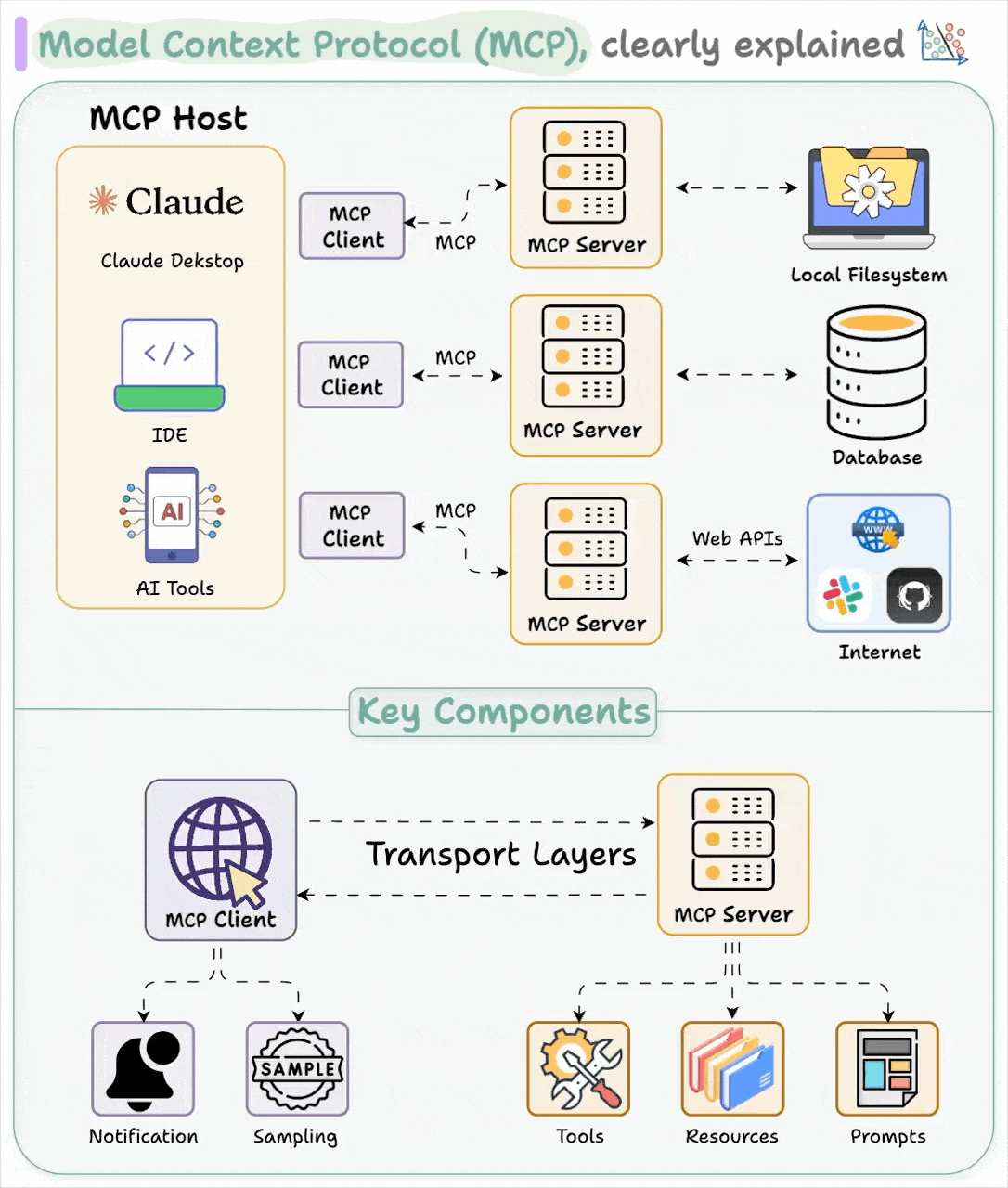
MCP 主機(Host)
這部分指的是利用大型語言模型運作並需要外部資料或功能的應用程式,例如聊天機器人、IDE 或其他嵌入 LLM 的工具。舉例來說,像 Claude Desktop、類似 Cursor 的程式碼編輯器或聊天介面,都可以扮演 MCP 主機的角色。主機負責調度 LLM 的操作、管理多重連線,並將從外部取得的資訊與 AI 的回應整合在一起,通常會結合一個或多個 MCP 客戶端。
MCP 客戶端(Client)
客戶端是嵌入在主機內部的元件(通常以函式庫或程序形式存在),負責與 MCP 伺服器建立一對一的連線。每一個數據來源或工具都會有專屬的客戶端實例,用來處理與伺服器之間的訊息往來、請求轉發與回應處理,同時也會記錄伺服器所提供的功能。客戶端還負責連線的初始化和能力協商等細節,確保整個通訊流程順暢無誤。
MCP 伺服器(Server)
伺服器則是輕量級的程式或服務,通過 MCP 介面向外部提供特定的數據或功能。這些伺服器可以封裝本地資源(如檔案系統或資料庫),也可以連接遠端服務(例如 Slack、Gmail、GitHub 等)。每個伺服器都以標準化的方式提供一項或多項功能,讓任何 MCP 客戶端都能發送查詢或調用相關服務。這樣一來,主機就不必針對每個外部服務編寫獨立的整合程式,只需通過 MCP 標準與所有伺服器通訊。早期的應用實例包括用於 Google Drive、Slack、Git repo 和 Postgres 資料庫的連接器。
許多人對此感到困惑,讓我們來釐清一些概念:
- ❌ **無法取代 API**: MCP 可以使用 API,但它只是一個標準化介面,並非取代特定 API 功能的工具。
- ❌ **建立並不複雜**: 開發者可以透過簡單的協議來建立 MCP 伺服器。網路上有許多模板、第三方資源可供參考。
- ❌ **並非直接的資料庫**: MCP 伺服器不會直接存儲數據,而只是充當一座橋樑。
此外,MCP 不僅限於遠端伺服器,也可以在本地運行。
MCP 協議(Protocol)
MCP 協議定義了客戶端與伺服器之間溝通的語言和規範。它採用 JSON-RPC 2.0 作為訊息格式,並建立了一套針對初始化、列出功能、工具調用等常見任務的標準方法和訊息類型。通訊可以通過多種傳輸方式實現,例如本地伺服器通常使用標準輸入/輸出流(stdio),而遠端伺服器則可利用 HTTP 與 Server-Sent Events(SSE)來維持連線。這一協議層負責訊息的編碼、交換與會話管理,確保連續多個請求能夠在同一連線中順利處理。
其他名詞解釋(補充)
由於 LLM 的相關議題範圍極廣,涉及眾多專有名詞,為了讓大家能夠更清楚地理解這些概念,以下整理了各個概念之間的差異與關聯。
什麼是 AI agent?
AI Agent 是一個能夠代替人類執行一系列操作以達成特定目標的智能系統。與傳統使用者單次輸入 prompt,然後讓 LLM 生成回應的互動模式不同,AI Agent 更像是一位具備目標導向的自主執行者。它會根據目標進行任務分析,將複雜任務拆分為多個子任務,再依照計劃自動做出決策與執行,直到最終完成任務。雖然有時候也稱為智能體、代理人,但為了避免過於抽象,我們更傾向於使用「AI Agent」這一術語,強調它在實際應用中的具體行動與任務完成能力。
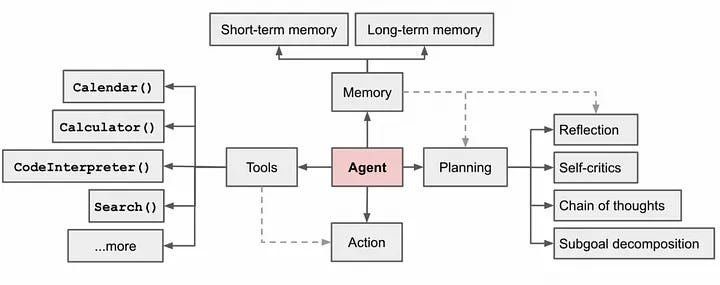
AI Agent 與 Function Calling 的關係
在執行任務的過程中,AI Agent 通常需要與外部系統互動,比如存取資料、調用其他服務等。這時,Function Calling 就扮演了一個重要的角色(又稱Tool Use)。它作為一種接口,使得 AI Agent 能夠調用各種外部工具或資源。換句話說,Function Calling 為 AI Agent 提供了擴展其功能的能力,使其不僅僅局限於內部的語言生成,而是能夠進一步完成更複雜的操作,像是數據檢索、記錄更新等。
AI Agent 與 LLM 模型的關係
AI Agent 的核心運作離不開大型語言模型的支撐。LLM 模型負責進行語言理解與生成,協助 Agent 進行任務分析、計劃制定以及步驟拆解。簡單來說,AI Agent 是以任務目標為導向的決策者,而 LLM 則是提供「思考」與回應的引擎。兩者密切合作:Agent 依賴 LLM 來產生合理的操作方案,並透過內部機制執行分解後的子任務,最終實現自動化的工作流程。
MCP 跟 Function Calling 差異在哪?
回到與本文的主題,雖然 MCP 與 Function Calling 都旨在幫助 AI 系統調用外部工具,但它們在設計理念上存在明顯不同。傳統的 Function Calling 通常需要將特定函式直接嵌入應用程式中,這種方式耦合度較高,每增加一項功能就可能需要撰寫對應的新程式碼。相比之下,MCP 提供了一個標準化的通訊協定,它解耦了 AI 主機與外部服務的關係。只要遵循 MCP 規範,開發者就可以讓 AI 應用透過統一接口調用多個 MCP 伺服器上的功能,而無需對每個外部 API 進行獨立整合。這樣不僅大幅簡化了開發流程,還提高了整體系統的擴展性與靈活性。
MCP 功能說明
MCP 協議允許伺服器向 AI 模型提供三大類功能:資料、工具和提示。這些功能使模型能夠根據需要獲取實時資訊、執行各種操作以及獲得最佳引導。以下分別介紹這三種功能類型:
- 資料(Resources):提供只讀、靜態內容(例如文件、資料庫記錄、維基頁面),使模型能動態獲取最新上下文資訊。
- 工具(Tools):定義可執行的函數或動作(如計算、API 查詢、訊息發送或記錄更新),讓模型能執行操作,通常需用戶確認以確保安全。
- 提示(Prompts):提供預設模板或多輪對話流程,引導模型完成特定任務,確保輸出一致並符合最佳實踐。
這三類功能在最終效果上都將資訊傳遞給模型的上下文窗口(通常以文字形式),但區分它們有助於客戶端根據需求進行恰當處理:工具需要參數傳遞和用戶確認,而資料則是直接提取並插入上下文。實際應用中,許多 AI 集成方案重點放在工具上,因為它們實現了主動操作;但資料與提示同樣在提供背景信息與最佳指導方面扮演著關鍵角色。透過這樣的功能組合,MCP 讓 AI 模型能夠更靈活地從各種資源中獲取信息,並在必要時執行具體動作,從而大幅提升整體系統的實用性與效率。
MCP 應用於 Claude Desktop (簡單實作)

如果對於Python環境搭建需求可以先參考 => 環境安裝指南
from mcp.server.fastmcp import FastMCP
# 建立一個 MCP 伺服器,這裡設定名稱為 "MCP-demo"
mcp = FastMCP(name="MCP-demo")
# 定義一個工具函式,用來計算傳入字串中 'r' 字母的出現次數
@mcp.tool()
def count_r(word: str) -> int:
"""
計算傳入字串中 'r' 字母出現的次數
參數:
word (str): 要檢查的字串
回傳:
int: 'r' 字母的數量,若輸入不是字串則回傳 0
"""
if not isinstance(word, str):
return 0
# 轉成小寫後計算 'r' 的數量
return word.lower().count("r")
# 定義一個資源函式,當客戶端請求 URI 為 "docs://document" 時,會回傳文件內容
@mcp.resource("docs://document")
def get_all_langgraph_docs() -> str:
"""
取得所有文件內容,回傳檔案內的文字
參數: 無
回傳:
str: LangGraph 文件的內容;若讀取失敗則回傳錯誤訊息
"""
# 設定本地文件所在的路徑
PATH = '/Users/yilintsai/Desktop/Demo/'
doc_path = PATH + "doc.txt"
try:
with open(doc_path, 'r') as file:
return file.read()
except Exception as e:
return f"讀取檔案錯誤:{str(e)}"
if __name__ == "__main__":
# 啟動 MCP 伺服器,這裡使用 stdio 作為傳輸方式
mcp.run(transport='stdio')
@@@的首都在台北
@@@的英文名稱為Taiwan
@@@最著名的美食為小籠包
{
"mcpServers": {
"MCP-demo": {
"command": "/Users/yilintsai/Desktop/MCP-countr/.venv/bin/python",
"args": [
"/Users/yilintsai/Desktop/MCP-countr/server.py"
]
}
}
}
如果你對 LLM 技術感到興趣,歡迎參考我的免費電子書《全民瘋AI系列 [大語言模型應用與實戰]》。本系列將會介紹基礎 LLM 觀念與實戰應用,手把手教您如何從環境建置到模型部署。此外,書中也整理了市面上各家語言模型供應商提供的免費額度資源,讓您輕鬆入門體驗 AI 的魅力。
全民瘋AI系列電子書
全民瘋AI系列 是一個專為 AI 學習資源打造的開源平台,由一群熱愛資料科學的工程師所組成。這個平台的宗旨是提供一個開放、協作的環境,讓更多人能夠方便地學習 AI 和機器學習相關技術,無論是初學者還是進階使用者,都可以在這裡找到適合的學習資源和工具。透過社群的力量,平台上的內容持續更新,涵蓋從基礎理論到實務應用,滿足不同層次的學習需求。